Google researchers find that Machine Learning could be better for Indexing
Current Techniques
Currently, we use techniques such as B Tree index to index data for fast searching. This is very important for various applications, mainly databases. Data warehouses can contain Petabytes or even Exabytes of data, and indexing them efficiently, both in terms of time and space, is very crucial.
Similarly, we use Hashing techniques for pinpointing a data item in a dataset. A common application is storing a small amount of key-value pairs in a Hashmap. Most common languages provide some sort of inbuilt implementation for Hashmaps, such as HashMap in Java or Map in C++
How they work?
Indexing and Hashing techniques work on some presumption about the data. For example, one assumption might be that the data is sorted. Another assumption could be that data is equally distributed over some region. These techniques work well when the data follows the assumption, and work poorly or even fail when it doesn’t. Thus, it is very important to properly decide what model the data follows. Is it sorted? Does it depict a bell curve? Are smaller strings more likely than larger strings? Answering these questions helps us choose, or develop the proper techniques to be used for indexing/hashing the data.
The problems
However, traditional techniques come with their own drawbacks, mainly
- They are generally designed for specific cases, or worst case scenario of data.
- It can be very costly(both in terms of time and manpower involved) to develop custom models for indexing/hashing.
- It can be very difficult to analyze the huge amount of data to find out what pattern it follows.
- Technique developed for one scenario might never be used again, i.e lack of reusability.
The solution
To overcome these problems, Google researchers have suggested that we can use Machine Learning to develop solutions for every case. Basically, we overcome the above problems as,
- The same ML program can be used to develop techniques for every case (after all, that is why we use ML)
- Cost effective as custom models don’t need to be manually coded.
- ML is already well known to effectively analyze and model large datasets
- No worry about reusability, just create a new model using ML.
In their own words, the researchers say,
all of those indexes remain general purpose data structures, assuming the worst-case distribution of data and not taking advantage of more common patterns prevalent in real-world data. …. knowing the exact data distributions enables highly optimizing almost any index… Of course, in most real-world use cases, the data does not perfectly follow a known pattern and the engineering effort to build specialized solutions for every use case is usually too high. However, we argue that machine learning opens up the opportunity to learn a model that reflects the patterns and correlations in the data and thus enable the automatic synthesis of specialized index structures, termed learned indexes, with low engineering cost.
What ML-based solution does?
When we use ML for, say Classification or Regression, what we basically do is take the training data, fit that data to some model, say a curve. Later, when we use it, the model will try to predict the result for given input.
Similarly, when we use ML for indexing, we first fit the data to some model, as shown in the image below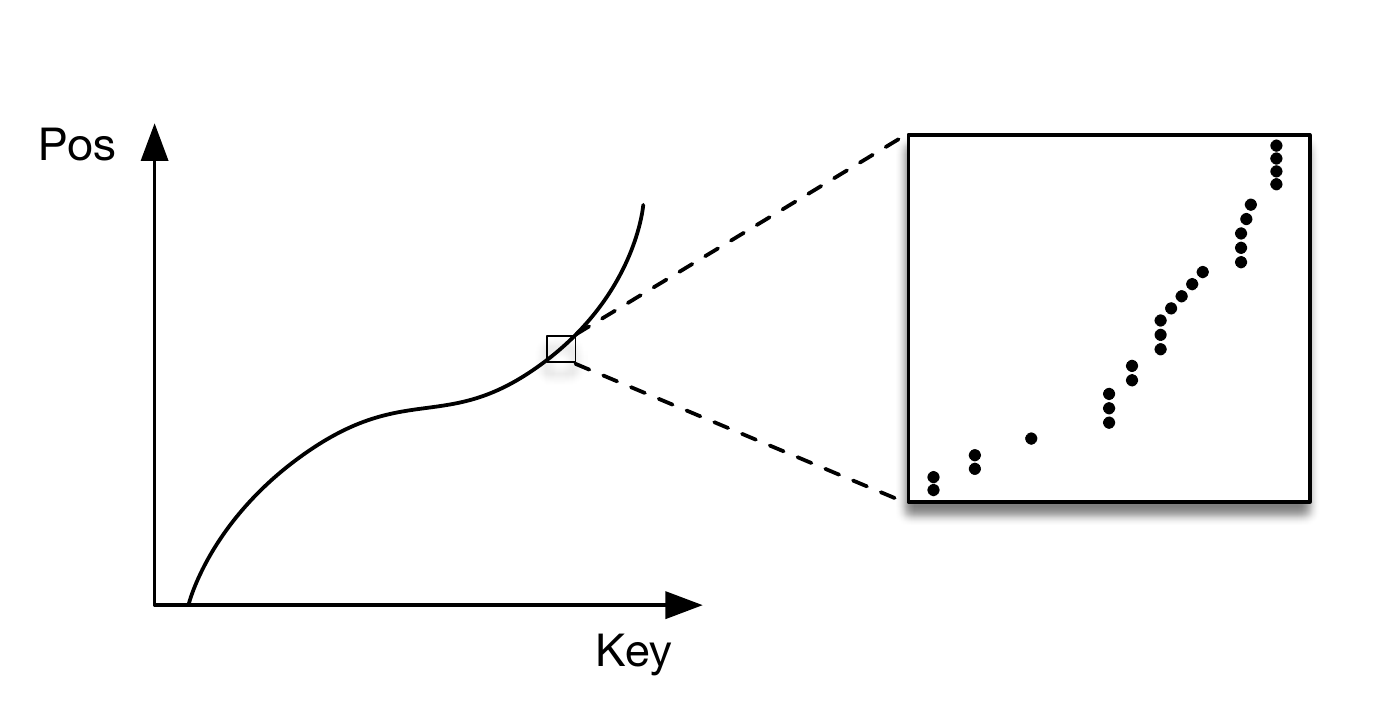 When we have to locate some data, we input the key, as usual. The difference is that the ML-based model would now try to predict where the data could be, and return that location.
When we have to locate some data, we input the key, as usual. The difference is that the ML-based model would now try to predict where the data could be, and return that location.
Results of the research
The results have been very impressive. One of the datasets that Google used is the Map dataset.
For the maps dataset Google indexed the longitude of ≈ 200M user-maintained features (e.g., roads, museums, coffee shops) across the world. The results for this dataset are shown in the table below.
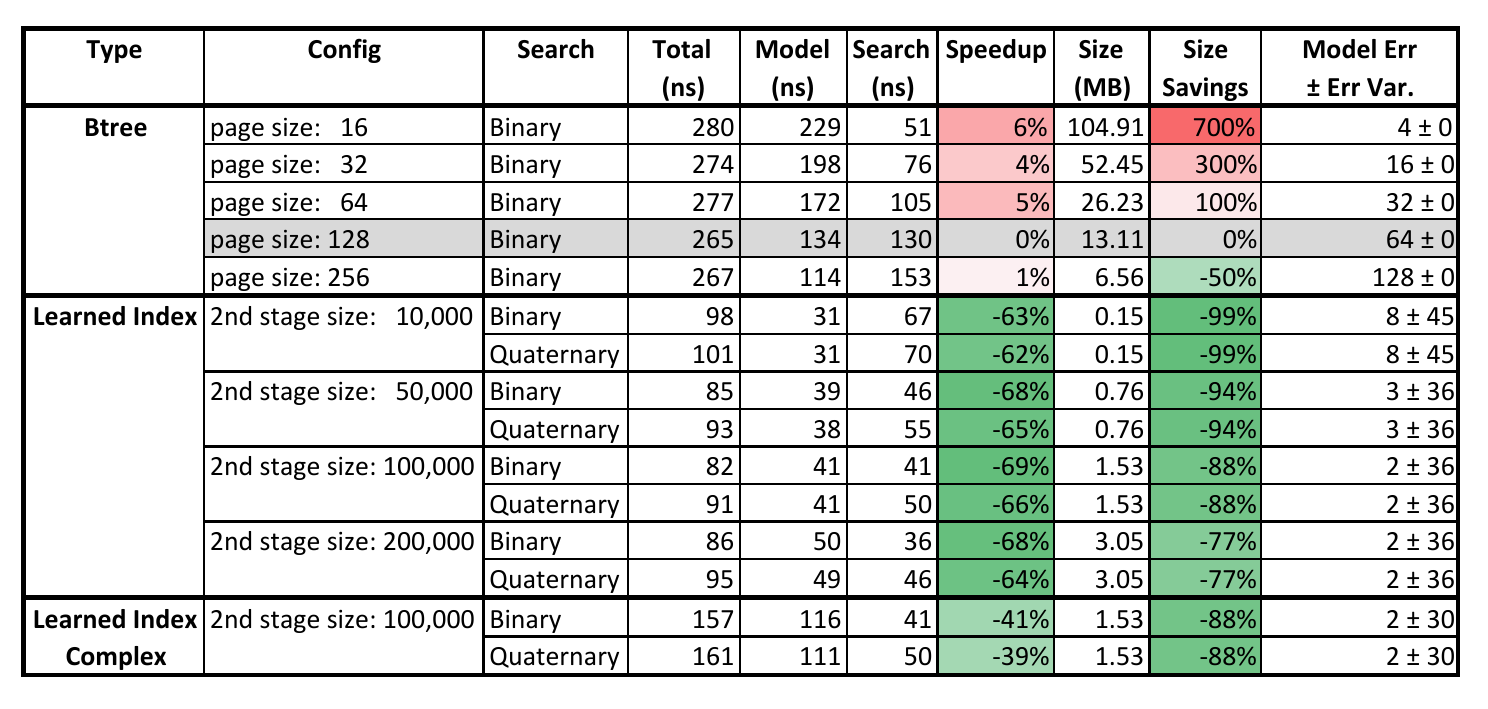 In their own words,
In their own words,
The current design, even without any significant modifications, is already useful to replace index structures as used in data warehouses, which might be only updated once a day, or BigTable where B-Trees are created in bulk as part of the SStable merge process
Conclusion
ML, when powered by Large datasets and enough computing power, can do wonders. With powerful GPUs becoming commonplace, even in Mobiles, and with the advent of Tensor Processing Units, which are optimized for ML work, ML and AI are very likely to become part of our daily life, both as a Programmer, and as an end user.
You can read the paper at Arxiv