Finding popular sites from data breach list
Recently, Troy Hunt added a new dataset of 2844 data breaches with 80M records to his “Have I been pwned” database. Along with this, Troy also provided a list of the names of the files containing this data. The files names look like they are related to the website to which they belong, for example, allcarbs.com.txt most likely relates to allcarbs.com. You can get the list here. The list looks like this,
www.hairpang.com.txt
www.hairsearch.eu.txt
www.hajam.hu.txt
www.handwerkerverbund-deutschland.de.txt
www.hapinemu.net.txt
www.happybanana-online.com.txt
www.happyhomefurnishers.co.uk.txt
www.happyhomefurnishers.com.txt
www.happyworkplace.com.txt
www.hartleyharvest.com.au.txt
www.hartsalesteam.com.txt
www.haru-design.jp.txt
www.hathawaycreativecenter.com.txt
www.hattrickgazette.org.txt
www.havanesegallery.hu.txt
www.havelikalbakken.no.txt
www.havelland-solar.de.txt
www.hbtv.us.txt
www.hcrapaddler.com.txt
www.hedaet.com.txt
www.hedgeconnection.com.txt
www.heimarbeit-verzeichnis.de.txt
I wanted to know if there are any popular sites on this list. However, there were a few issues. Firstly, the list was too long to read it completely. Secondly, it was sorted alphabetically, while for my purpose, it would have been better if it were sorted by popularity. So I decided to parse this list myself.
Getting the domain names
For most of the names in the list, the format is domain name + .txt. So I started by removing the .txt part from the list. The following one-liner fixed it.
cat domains | sed s/\.txt$//g | sort > sorted.txt
sed replaces .txt with nothing. As . is a special character in regex, it needs to be escaped with a \. I added a sort, just in case the file wasn’t sorted already.
How to rank the domains?
The next issue was how I would go about ranking the domains. The first name that came to my mind was alexa. Alexa provides a ranking for websites, which is based on last 3 months traffic to the website. I also looked at ProgrammableWeb to see if there are any other interesting APIs. While Webfinery’s API seemed the most relevant, the free version was limited to only 100 requests/day. That way, it would have taken me a whole month. So I went ahead with Alexa’s API.
The Alexa API is available on aws. It isn’t the best one out there. First of all, it returns XML, rather than JSON. Secondly, there doesn’t seem to be a lot of flexibility in user’s ability to access specific data (GraphQL, anyone?). But it was what I had.
Using the API
Luckily, aws provided sample programs to use this API. I selected the Java program from the available options. The program takes 3 inputs, 2 of them being credentials, and third being a domain name whose information has to be retrieved.
Executing the program as java UrlInfo ACCESS_KEY_ID SECRET_ACCESS_KEY www.google.com gave this output,
Making request to:
https://awis.amazonaws.com/api?Action=urlInfo&ResponseGroup=Rank&Url=www.google.com
Response:
<?xml version="1.0" ?>
<aws:UrlInfoResponse xmlns:aws="http://awis.amazonaws.com/doc/2005-10-05">
<aws:Response xmlns:aws="http://awis.amazonaws.com/doc/2005-07-11">
<aws:OperationRequest>
<aws:RequestId>29fec3c3-1bdb-11e8-b3f8-0325f3b17994</aws:RequestId>
</aws:OperationRequest>
<aws:UrlInfoResult>
<aws:Alexa>
<aws:Request>
<aws:Arguments>
<aws:Argument>
<aws:Name>url</aws:Name>
<aws:Value>www.google.com</aws:Value>
</aws:Argument>
<aws:Argument>
<aws:Name>responsegroup</aws:Name>
<aws:Value>Rank</aws:Value>
</aws:Argument>
</aws:Arguments>
</aws:Request>
<aws:TrafficData>
<aws:DataUrl type="canonical">google.com/</aws:DataUrl>
<aws:Rank>1</aws:Rank>
</aws:TrafficData>
</aws:Alexa>
</aws:UrlInfoResult>
<aws:ResponseStatus xmlns:aws="http://alexa.amazonaws.com/doc/2005-10-05/">
<aws:StatusCode>Success</aws:StatusCode>
</aws:ResponseStatus>
</aws:Response>
</aws:UrlInfoResponse>
More data than I needed, but it had what I required. The tag <aws:Rank> gives, as you might have guessed, the global rank of the website.
Getting the required data
The next step was to parse the XML to get only the rank. While this could be done with an XML parser library, it would have been an overkill as I needed only a single line, which could easily be separated using CLI tools such as grep, awk or sed.
I used the following command to get the rank.
java UrlInfo ACCESS_KEY_ID SECRET_ACCESS_KEY www.google.com|grep "<aws:Rank>"|sed s/\<[a-zA-Z:/]*\>//g
The grep command displays only those lines which have <aws:Rank> in them. The sed command then replaces any occurrence of the regex with nothing, thus keeping only the rank. The pattern looks for a string which contains any of a to z, A to Z or : and /.
Putting everything together in a script
I put the above command in a bash script. The script loops through the file of domains, and for each domain, it appends the name and it’s rank to the file. For domains whose rank is not available, or for those lines where the domain names are invalid, it does not retrieve a rank.
#! /bin/bash
while read -r line || [[ -n "$line" ]]; do
rank=$(java UrlInfo ACCESS_KEY_ID SECRET_ACCESS_KEY $line | grep "<aws:Rank>"|sed s/\<[a-zA-Z:/]*\>//g)
echo $line $rank >> ranked.txt
done < "$1"
This script takes the file name as argument. For example, ./script.sh sorted.txt
Speeding up the 🐌
There were two issues with the API. Firstly, it was quite slow. It takes upwards of 10 seconds, sometimes even 20 seconds to return the output. I had to speed it up. The easiest way I found to do this is to split the input file into multiple files, and then run the script in parallel on each one.
Luckily, split and GNU Parallel do exactly this. To split the file, I ran,
split -l 100 sorted.txt
This splits the file into parts with 100 lines each. The files are named as xaa xab xac by default.
Then, to run the script in parallel on all those files, this GNU Parallel command came to the rescue.
ls x* | parallel ./script.sh {}
Parallel replaces {} with one of the inputs that were piped to it, which in this case is the name of one of the split files.
Eye Candy
While the work was being done, I needed a way to monitor the output file size, CPU usage and network usage. What better way to do this, other than tmux?
Using tmux(for split screen terminal), bwm-ng(for network monitoring) and watch(for monitoring file size), I got this,
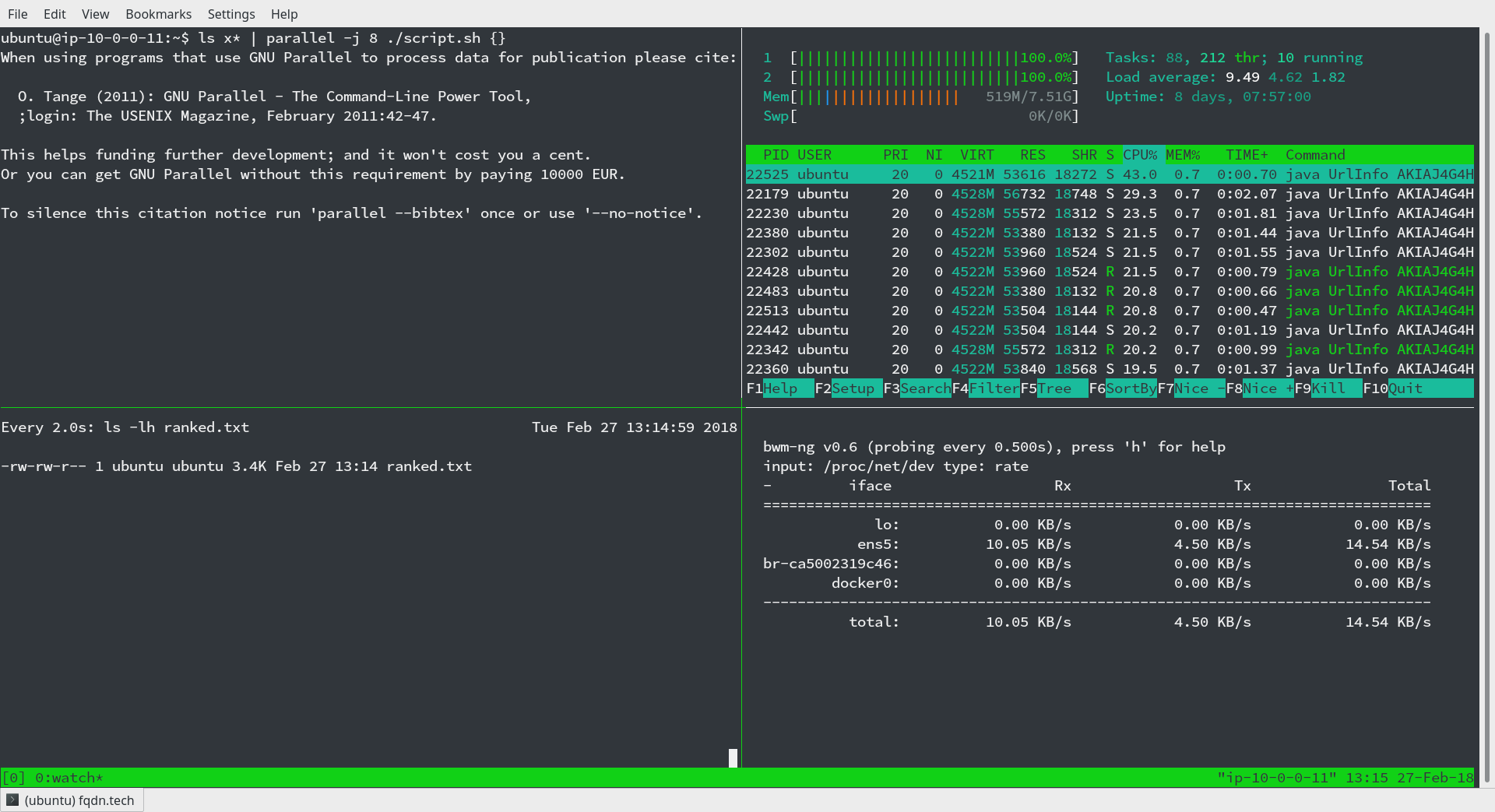
Final Steps
Finally, I had to sort the output file by the second column. sort’s -k option is useful for this.
sort -k2n -k1,1 ranked.txt >ranksorted.txt
This sorts the file by second columns, and then the first column in case of a tie. The result isn’t perfect, as many “domains” weren’t FQDNs, and many of them didn’t have a rank on Alexa. Yet, the result was closer to what was needed for my purpose.
Findings
Some sites in this list are quite popular ones, like libero.it, which is ranked 530th in the world, while being 10th in Italy. Similarly moneycontrol.com is 631st in the world while being 42nd in India. Other popular sites include plex.tv and nptel.ac.in, which is a site that provides courses from IITs, and Malwarebytes.org.
You can find this file on github here.